kubernetes eviction
1. 前言
在某些情况下 k8s 会出现 evicted 的 pod, 然而这并不在 pod 的生命周期中.这就是 k8s 的驱逐机制。
当机器的一些资源(内存、磁盘)过小时,为了保证 node 不会受到影响,会将 pod 驱逐至其他的机器上
2. 资料
可以在 这里看到相关资料
来看一下代码中,驱逐策略是怎样实现的
3. 代码详解
3.1. 代码参考
3.2. 详解
pkg/kubelet/apis/kubeletconfig/v1beta/default.go
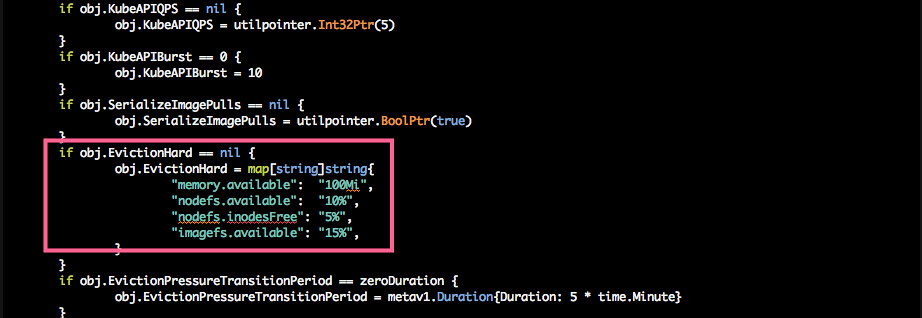
定义了这几个默认值作为阈值
pkg/kubelet/kubelet.go

kubelte 初始化了 eviction manager
在 runtime 相关模块被加载时,eviction manager 被加载进来
开始了 evict 相关的控制循环
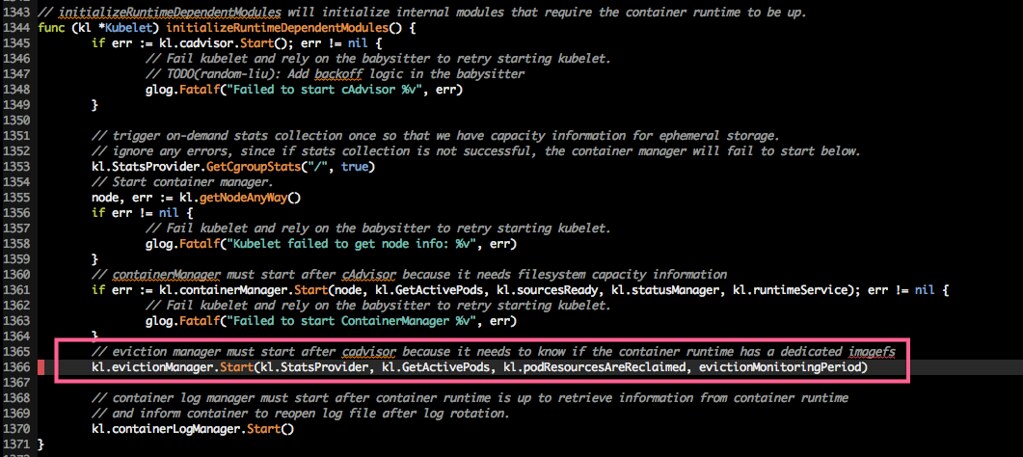
接下来是 evict 真正工作的代码
代码目录是 pkg/kubelet/eviction/
主要看该目录下的两个文件 evictionmanager.go helpers.go
pkg/kubelet/eviction/evictionmanager.go
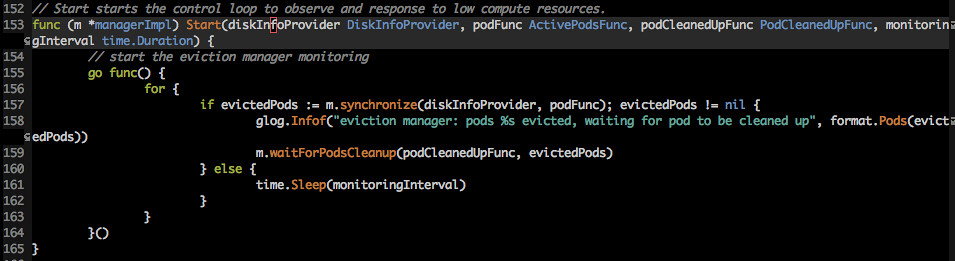
Start 是 evict manager 的入口
这里是一个死循环
循环中的主要函数是 synchronize 用来清理 pod、同步信息。这个就是今天的主角
先看一下 synchronize 的参数 diskInfoProvider podFunc
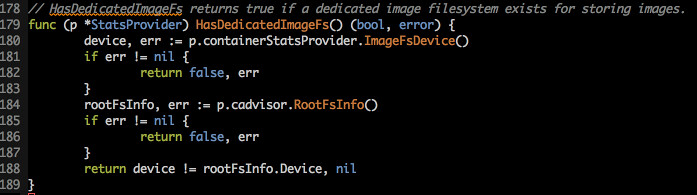
diskInfoProvider 是一个接口,用来提供磁盘的信息,作为是否发生驱逐的依据。实际函数在 pkg/kubelet/stats/ 下
synchronize 中仅用到了 HasDedicatedImageFs
podFunc 用来获取一个待检查的 pod 列表,实际函数在 pkg/kubelet/kubeletpods.go

首先检查 imagesfs, 数据从 cadvisor 中获取
获得容器信息和 kubelet 总计状态

summaryProvider 的实际函数在 /pkg/kubelet/server/stats/summary.go
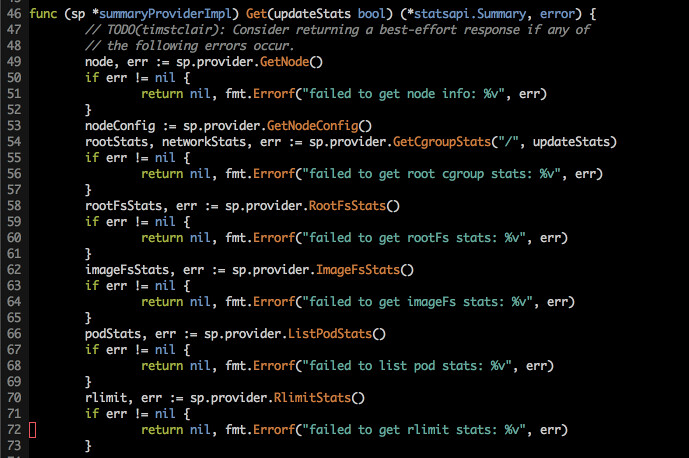
开始监视当前的系统状态

监视这些数据 Node.Memory allocatableContainer.Memory nodeFs.AvailableBytes nodeFs.InodesFree Node.Runtime.ImageFs NumOfRunningProcesses
比较阈值与观测到的数据


对数据去重、记录时间、确定在一段时间内仍处于不良状态
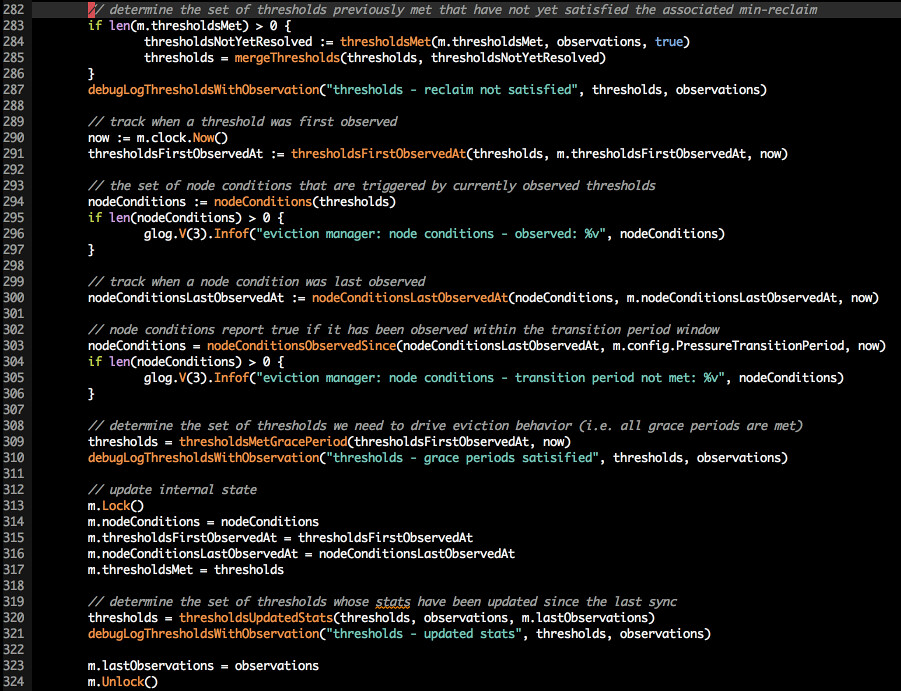
开始进行驱逐
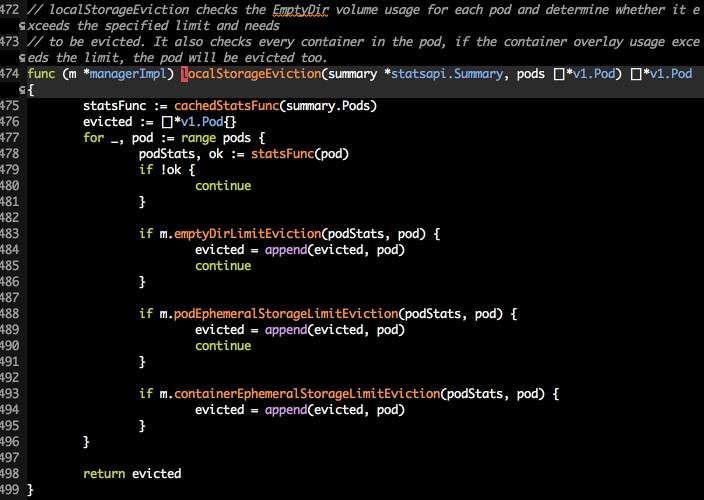
如果 apiserver 中 LocalStorageCapacityIsolation 这个参数为 true (1.10 默认打开), 那么 localstorage 的驱逐仅会发生在 localStorageEviction 内部

根据之前获得的信息与并于阈值做比较之后,小于阈值的资源的 pod 列表,并将其排序
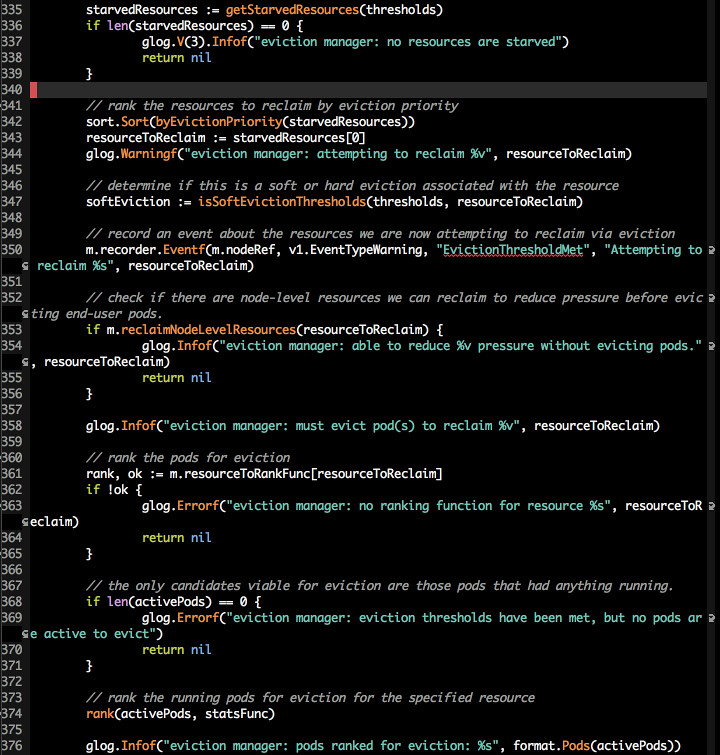
排序的方式如下

在执行驱逐前记录驱逐的时间
开始驱逐
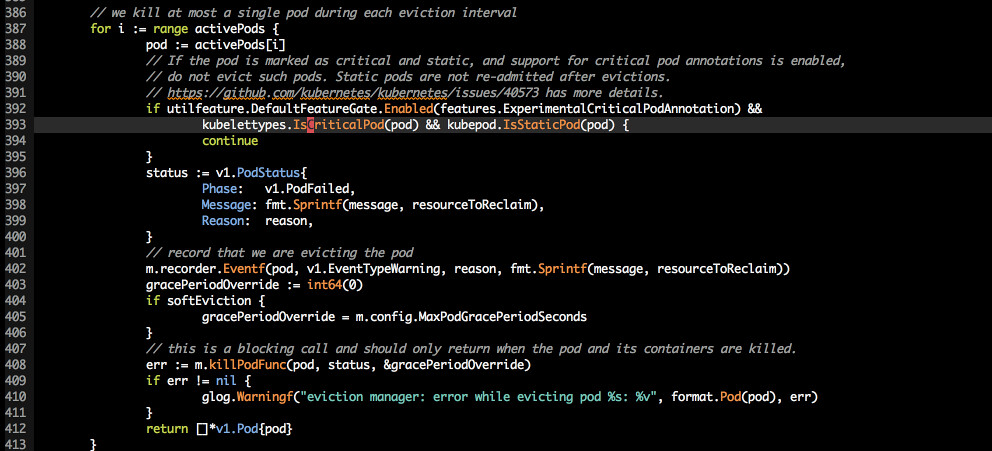
在 ExperimentalCriticalPodAnnotation (1.10 默认关闭) 打开的情况下, 如果即是 critical pod 又是 static pod 及不会出发驱逐
如果当前的资源不再是高于阈值的资源或者没有立即进行驱逐的信号则进行软驱逐-等待一段时间
否则直接杀掉 pod